Metody dobývání znalostí z databází (data mining): Porovnání verzí
| Řádek 44: | Řádek 44: | ||
[[Umělá inteligence]]<br /> | [[Umělá inteligence]]<br /> | ||
[[Statistika]]<br /> | [[Statistika]]<br /> | ||
| − | [[Datové struktury]] | + | [[Datové struktury]]<br /> |
| + | [[Big data]]<br /> | ||
| + | [[Rozhodovací tabulky a stromy]] | ||
=== Externí odkazy=== | === Externí odkazy=== | ||
| Řádek 51: | Řádek 53: | ||
=== Klíčová slova === | === Klíčová slova === | ||
Získávání znalostí z databází, data mining, datová analýza, dolování dat, dobývání znalostí z databází | Získávání znalostí z databází, data mining, datová analýza, dolování dat, dobývání znalostí z databází | ||
| − | |||
| − | |||
| − | |||
| − | |||
[[Kategorie: Informační studia a knihovnictví]] | [[Kategorie: Informační studia a knihovnictví]] | ||
[[Kategorie: Státnicové otázky UISK]] | [[Kategorie: Státnicové otázky UISK]] | ||
Aktuální verze z 4. 6. 2018, 17:12
"Dobývání znalostí z databází (také data mining) je netriviální proces poznávání platných, dosud neznámých, potenciálně užitečných a srozumitelných vzorů v datech.[1]"
Data mining se tedy chápe jako proces hledání vzorů v datech, vzor znamená určitý platný vztah na konkrétním souboru dat vyjádřený ve srozumitelné podobě. Podoba zahrnuje některé z forem modelů dat např. rozhodovací stromy, asociační pravidla, shlukové analýzy apod.
Data mining se používá pro zjišťování nových poznatků a hypotéz v protikladu ke klasické statistické analýze, která má za cíl je potvrdit nebo vyvrátit. Důvodem pro to, je velké množství různých druhů dat, se kterými operuje většina organizací, a ve kterých se můžou ukrývat dosud neznámá zajímavá zjištění.
Obsah
Historie
Rozvoj data miningu podmiňoval v 70. a 80. letech 20. století nárůst výkonu a paměti počítačů, vývoj databázových technologií a počátku výzkumu umělé inteligence. Šířeji aplikovat se začal na počátku 90. let v USA v komerčním sektoru. Velké organizace vytvářely tak velké množství dat, že se již klasickými metodami nedaly analyzovat. Data mining se nejvíce používal v bankovnictví, pojišťovnictví, maloobchodním prodeji, přímém marketingu apod. V dnešní době big data “velkých dat”, se používání data miningu neustále zvyšuje, hojně se využívá např. web mining (získávání znalostí z webu) nebo text mining (získávání znalostí z dokumentů).
Metodologie
Ačkoliv není CRISP-DM jedinou standardizovanou metodologií vyvinutou pro data mining (viz např. SEMMA pro proprietální SAS), je nejuniverzálnější a nejčastěji používanou. CRISP-DM (Cross Industry Standard Process for Data Mining) byla vyvinuta v rámci výzkumného projektu Evropské komise a podílelo se na ní několik komerčních firem se zkušenostmi s data miningem. CRISP-DM popisuje jednotlivé oblasti data miningu s důrazem na vracení se k předchozím fázím a jejich neustálé upravování.
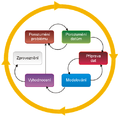
CRISP-DM

Popis fází
- Porozumění problematice (Business Understanding) - zadání úlohy a cíle data miningu, může být vemi hrubé vymezení toho, co chce uživatel znát.
- Porozumění datům (Data Understanding) - posouzení smyslu, kvality a významnosti dat.
- Příprava dat (Data Preparation) - příprava dat před modelováním. Zahrnuje čištění dat, transformaci dat, slučování dat, práci s chybějícími hodnotami apod.
- Modelování (Modeling) - tvorba modelů.
- Vyhodnocení výsledků (Evaluation) - ověření správnosti modelů.
- Využití výsledků (Deployment) - využití výsledků v praxi, z hlediska zadavatele nejdůležitější fáze.
Z praktického hlediska je časově nejnáročnější oblast přípravy dat. Pro úspěch data miningu jsou nejdůležitější fáze porozumění problematice, datům a využití výsledků. Uživatel se tak vyhne riziku tzv. GIGO (Garbage In - Garbage Out) - když nesmyslná a nepochopená vstupní data vedou ke špatným výsledkům.
Typy úloh
Základní typy úloh, které se odvíjejí od cílů data miningu se rozdělují na -
- Predikce (klasifikace) - po klasifikaci na trénovací množině dat uživatel chce předpovídat další neznámé objekty např. analýza bonity potenciálního klienta.
- Deskripce - uživatel chce získat povědomí o datech jako celku a orientovat se v nich, např. analýza nákupního košíku.
- Hledání nuggetů - uživatel chce zjistit některé zajímavé odchylky od normálních hodnot, např. identifikace podvodníka.
Vybrané metody
Statistické -
- Kontingenční tabulky
- Regresní analýza
- Shluková analýza
- Diskriminační analýza
Strojové učení -
- rozhodovací stromy
- neuronové sítě
- Bayesovské sítě
- rozhodovací pravidla
Odkazy
Reference
- ↑ FAYYAD, Usama M. Advances in knowledge discovery and data mining. Menlo Park: AAAI Press, c1996.
Použitá literatura
- BERKA, Petr. Dobývání znalostí z databází / Petr Berka. 2003. ISBN 8020010629.
- MAŘÍK, Vladimír, Olga ŠTĚPÁNKOVÁ a Jiří LAŽANSKÝ. Umělá inteligence (4). Praha: Academia, 2003. ISBN 8020010440.
- WITTEN, I. H., Eibe FRANK a Mark A. HALL. Data mining [electronic resource]: practical machine learning tools and techniques / Ian H. Witten, Eibe Frank, Mark A. Hall. 2011. ISBN 9780123748560.
Související články
Umělá inteligence
Statistika
Datové struktury
Big data
Rozhodovací tabulky a stromy
Externí odkazy
- PLCHÚT, Martin. Dobývání znalostí z databází: Úvod a oblasti aplikací. Fakulta informačních technologií VUT [online]. [cit. 2018-05-20]. Dostupné z: http://www.fit.vutbr.cz/study/courses/ZZD/public/seminar0304/Uvod.pdf
- What is the CRISP-DM methodology?. Smart Vision Europe [online]. [cit. 2018-05-20]. Dostupné z: https://www.sv-europe.com/crisp-dm-methodology/
Klíčová slova
Získávání znalostí z databází, data mining, datová analýza, dolování dat, dobývání znalostí z databází
Text je dostupný pod licencí Creative Commons Uveďte autora 3.0 Česko při dodržení případných autorských práv a dalších podmínek
© 2013 ISSN: 2336-5897